For the past few months, I’ve led the EPAM Sitecore Competency Center. It’s been interesting times, to say the least! Much of 2020 was devoted to learning my new role as global head of the Sitecore CC and responding to the Covid-19 pandemic.
Both of these were largely focused internally — but I do hope to write a few posts about some of the interesting accelerators and proofs-of-concept that my fellow EPAMers created during those slow, uncertain months earlier this year. (We’ll showcase several of these at Sitecore Symposium next week.)
But for this post, I’d like to focus on the future, and the 6 themes that will drive digital platforms in 2021:
- Decoupled digital systems
- Cloud-native architecture
- Microservices and API-first development
- Optimized digital journeys
- Applied testing and analytics
- Unified experience profiles
Decoupled digital systems
Decoupling is a strategy in software architecture and code to separate concerns. By splitting features and functions into logically and/or physically separate routines, you can evolve these pieces of a system or program independently. This often improves scalability and maintenance. For content management systems, this means adopting the old idea of the two-stack CMS — treating the management application differently from the content delivery application.
This means you have the ability to tailor experiences for specific devices and for specific purposes. Decoupling also helps reduce the dependencies, which can help speed delivery.
The most extreme form of this can be found in the new wave of “headless” CMS providers, like Contentstack and Contentful. These focus on the management and administration of content through the use of well-defined APIs. But the “head” of the CMS — the delivery side — is all up to you. Sitecore and other CMS platforms are taking a less extreme approach. They provide a head — along with many of the advanced features that come with it — but decouple it from the back-office management application.
Whether you find a truly headless platform or merely a decoupled one a better fit for your needs, it’s clearly the driving theme in digital applications at the moment.
Cloud-native architecture
Many organizations have been surprised to find the benefits of moving to cloud hosting were not what they expected. McKinsey does a great job deconstructing these myths about the cloud. The core insight is that if you treat the cloud simply as “someone else’s datacenter”, you won’t get many of the improvements touted for cloud migration. To reap the benefits, you have to redesign your systems to take advantage of the flexibility that cloud architectures provide. “Lift and shift” is just a first step.
This applies not only to your own organization’s systems, but to many of the software platforms and services you’ve relied on. Most of these will move to a Software-as-a-Service model, and that means designing your systems as loosely connected independent services. That means less code, more configuration, and more integration.
Microservices and API-first development
API-first development underpins my first two themes. By separating concerns into distinct domain services, each with their own API contracts, you improve re-usability and add flexibility to your systems. These small web services can then be scaled and tuned for performance independently of each other.
So the first three trends mutually reinforce each other. Decoupling will lead you to making smaller, more focused applications and services. Standardizing the APIs for these will allow these services to be consumed by and composed into new offerings. And cloud-native architecture will allow these pieces to flex to meet demand and performance targets.
The first three themes were technical; the next three themes have to do with customer experience.
Optimized digital journeys
The recent pandemic underscored the primacy of digital channels for many organizations. And it’s clear that consumers and constituents reward organizations that provide the best digital experiences — through increased sales, positive reviews, and loyalty among other measures. But how can we provide a better digital experience?
The short answer is: figure out what a visitor is trying to do today and make it easy for them to do it. I emphasize the “today” in the last sentence, because often organizations undertake massive data mining operations to study past behavior or try to apply AI or advanced statistical techniques — or perhaps ignore the issue altogether because these projects seem too expensive or complicated! It doesn’t have to be either one of these extremes. It can start with the first question every human customer service representative is trained to ask, “What can I help you with today?”
You can ask this question of your visitors explicitly, or you can use other signals to determine what a visitor is trying to do — like which link an an email the visitor clicked to bring them to the site. Or which social media post they followed. Or what article they landed on through organic search. All of these are useful signals that you can use to help guide and personalize their journey in real time.
And the metrics are also easy to gather. How long did it take them to register an account, check out their cart, or fill out the form? After engaging in one of these journeys, did they respond to your survey? Did they share the article with friends? The chances are, your organization is already collecting much of the information you’d need to optimize the important journeys on your site. Often what organizations lack is time to reflect on these metrics and the know-how required to conduct small experiments. Which leads us to our next theme.
Applied testing and analytics
There’s a big difference between organizations that collect analytics to report status and those that actually apply it to drive improved business outcomes. And 2021 is the year you’ll see the latter kind of organization pull away from the former, due to the disruption caused by the pandemic.
Consumers have had to break a lot of their old habits and adopt new ones. So the companies that can ask smart, targeted questions about critical moments in the customer journey — and then take action on their findings — will distinguish themselves in the marketplace.
There are a range of tools and techniques you can apply. You can do A/B or multivariate tests, measure click-through rates, perform path analysis, conduct focus groups, or provide customer satisfaction surveys. But the tools are less important than being curious and asking interesting questions about the touch-points that serve your customers’ needs.
Unified experience profiles
Once you’ve embraced an experimental mindset and have begun making optimizations, you might be ready for the next step — creating a unified experience profile across all of your digital touch-points.
There are many reasons why a unified, 360-degree view of the customer is beneficial to your organization. One is that it enables you to serve your customers better. For example, your sales team will know what customer support told the customer. When a customer updates profile data, all your systems can see that change. Another is that you can derive new insights about your customers by viewing their behaviors across different channels. And a final reason is that you can better manage sensitive personal information within a comprehensive system than by scattering across numerous back-office systems.
This is a tall order, given the number of functions within your enterprise that rely on this data. Implementing a comprehensive view of customer data is a multi-year effort. But what makes this a powerful theme for 2021 is both the pandemic, which has emphasized digital remote work and de-emphasized paper and face-to-face transactions, as well as privacy and confidentiality regulations worldwide.
Many organizations are well on their way to implementing a 360-view. But harnessing its benefits — not simply reacting to events — will lead to many interesting opportunities.
Summing up
These 6 themes form the new digital playbook that many leading-edge organizations follow as they launch and scale their enterprises. The enterprise solutions I’m working on now involve many, if not all, of these themes.
We’ll be talking about these themes at Sitecore Sympsoium. I’m curious about whether these themes will resonate with others in the Sitecore community and in the wider digital ecosystem.
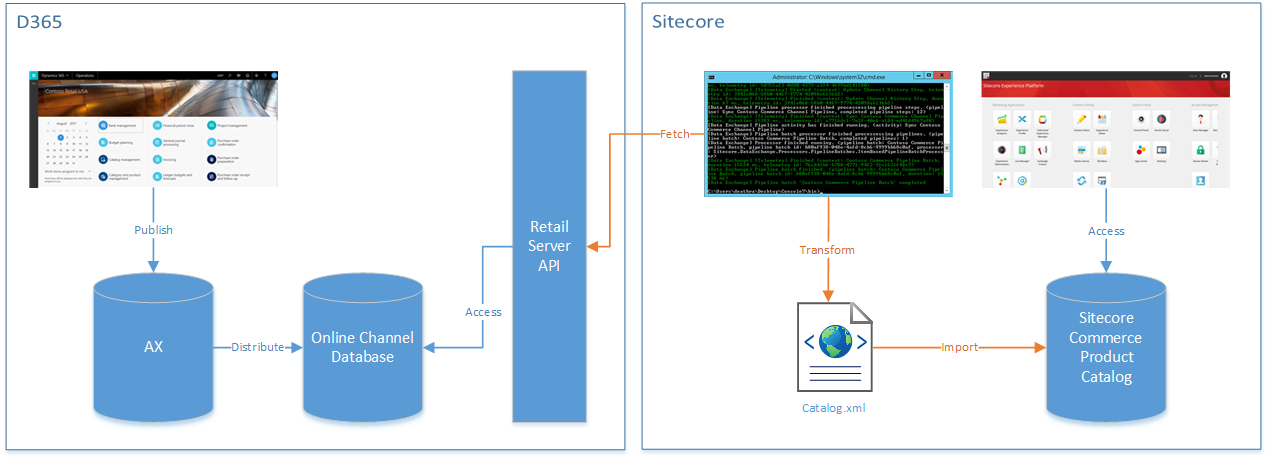
 This is the second time I’ve been a Sitecore MVP, my first award having been for Commerce in 2018. This year, I’ll be continuing my work with the Sitecore Commerce – Microsoft D365 Retail connector as well as getting involved in my company’s Sitecore Commerce – Hybris connector.
This is the second time I’ve been a Sitecore MVP, my first award having been for Commerce in 2018. This year, I’ll be continuing my work with the Sitecore Commerce – Microsoft D365 Retail connector as well as getting involved in my company’s Sitecore Commerce – Hybris connector.